导读:javaSE
1.1、原理
1.1.1、简述类加载机制
答:Java中的所有类,都需要由类加载器装载到JVM中才能运行。类加载器本身也是一个类,而它的工作就是把class文件从硬盘读取到内存中。在写程序的时候,我们几乎不需要关心类的加载,因为这些都是隐式装载的,除非我们有特殊的用法,像是反射,就需要显式的加载所需要的类。
javaSE
1.1、原理
1.1.1、简述类加载机制
答:Java中的所有类,都需要由类加载器装载到JVM中才能运行。类加载器本身也是一个类,而它的工作就是把class文件从硬盘读取到内存中。在写程序的时候,我们几乎不需要关心类的加载,因为这些都是隐式装载的,除非我们有特殊的用法,像是反射,就需要显式的加载所需要的类。
Java类的加载是动态的,它并不会一次性将所有类全部加载后再运行,而是保证程序运行的基础类(像是基类)完全加载到jvm中,至于其他类,则在需要的时候才加载。这当然就是为了节省内存开销。
Java的类加载器有三个,对应Java的三种类:
Bootstrap Loader // 负责加载系统类 (指的是内置类,像是String)
- - ExtClassLoader // 负责加载扩展类(就是继承类和实现类)
- - AppClassLoader // 负责加载应用类(程序员自定义的类)
1.1.2、简述JVM的常用参数
答:-Xss128k -Xmn5M -Xms10M -Xmx10M表示每个线程的大小是128k,新生代5M,可用堆内存10M,最大可用内存为10M
-Xss 设置每个线程的栈内存大小
-Xmn 设置新生代大小
-Xms 设置堆内存的初始内存大小
-Xmx 设置堆内存的最大可用大小
1.1.3、简述GC的基本原理
答:当程序员创建对象时,GC就开始监控这个对象的地址、大小以及使用情况。通常,GC采用有向图的方式记录和管理堆中的所有对象。通过这种方式确定哪些对象是"可达的",哪些对象是"不可达的"。当GC确定一些对象为"不可达"时,GC就有责任回收这些内存空间。
1.1.4、栈和堆的区别?什么时候用栈?什么时候用堆
a)栈是JVM为正在调用的方法自动分配的一块对应的空间,也就是栈帧,用于存储正在调用的方法中的所有局部变量(包括参数),当方法调用完成时,其对应的栈帧被清除,局部变量失效。
b)堆是由程序员控制申请分配的一块内存空间,用于存储所有new出来的对象(包括成员变量),在对象创建时被申请分配的内存同对象回收时一并被回收,内存释放工作由程序员控制,容易产生内存泄漏。
一般来说在方法中用栈,在类中用堆。
1.2 集合
1.2.1、List、Map、Set三个接口,存取元素时,各有什么特点
答:List 以特定次序来持有元素,可有重复元素;Set 无法拥有重复元素,内部排序;Map 保存key-value值,value可多值。
List表示有先后顺序的集合,当我们多次调用add(Obj e)方法时,每次加入的对象按先来后到的顺序排序。有时候,也可以插队,即调用add(int index,Obj e)方法,就可以指定当前对象在集合中的存放位置。一个对象可以被反复存储进List中,每调用一次add方法,这个对象就被插入进集合中一次,其实,并不是把这个对象本身存储进了集合中,而是在集合中用一个索引变量指向这个对象,当这个对象被add多次时,即相当于集合中有多个索引指向了这个对象。
List与Set具有相似性,它们都是单列元素的集合,所以,它们有一个功共同的父接口,叫Collection。Set里面不允许有重复的元素,所谓重复,即不能有两个相等(注意,不是仅仅是相同)的对象 ,即假设Set集合中有了一个A对象,现在我要向Set集合再存入一个B对象,但B对象与A对象equals相等,则B对象存储不进去,所以,Set集合的add方法有一个boolean的返回值,当集合中没有某个元素,此时add方法可成功加入该元素时,则返回true,当集合含有与某个元素equals相等的元素时,此时add方法无法加入该元素,返回结果为false。Set取元素时,没法说取第几个,只能以Iterator接口取得所有的元素,再逐一遍历各个元素。
Map与List和Set不同,它是双列的集合,其中有put方法,定义如下:put(obj key,obj value),每次存储时,要存储一对key/value,不能存储重复的key,这个重复的规则也是按equals比较相等。取则可以根据key获得相应的value,即get(Object key)返回值为key 所对应的value。另外,也可以获得所有的key的结合,还可以获得所有的value的结合,还可以获得key和value组合成的Map.Entry对象的集合。
1.2.2、HashMap和Hashtable的区别
答:HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,在只有一个线程访问的情况下,效率要高于Hashtable。
HashMap允许将null作为一个entry的key或者value,而Hashtable不允许。
HashMap把Hashtable的contains方法去掉了,改成containsvalue和containsKey。因为contains方法容易让人引起误解。
Hashtable继承自Dictionary类,而HashMap是Java1.2引进的Map interface一个实现。
最大的不同是,Hashtable的方法是Synchronize的,而HashMap不是,在多个线程访问Hashtable时,不需要自己为它的方法实现同步,而HashMap 就必须为之提供外同步。
Hashtable和HashMap采用的hash/rehash算法大概一样,所以性能不会有很大的差异。
1.2.3、hashmap存储原理
HashMap是一种‘链表散列’的数据结构,即:数组与链表的结合体。
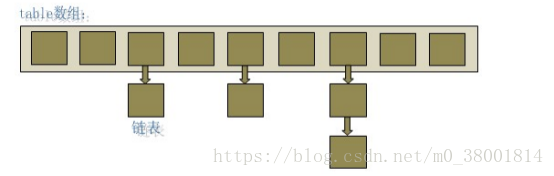
存储:
在hashMap中进行存储是利用put方法来进行的,当进行put操作的时候,如果key存在,新的值会将旧的值进行覆盖(特别值得注意的是:当key存在的情况下,会返回一个旧的值,如果不存在key,就会返回null)。
细节:
当进行put操作的时候,先根据hashCode重新计算hash值,根据hash值计算得到这个元素在数组中的下标位置,如果这个下标中已经存在元素,那么这个位置的元素将以链表的形式存储,新加入的元素放在表头,早先加入的就放在链尾;如果没有就直接将元素放在该数组指定下标位置中。
1.2.4、Hashset和Treeset的区别
LinkekHashSet会记录放入hashset中的元素顺序,可以按顺序遍历出来。Sortedset会对集合中的元素进行排序;treeset是sortedset的一个实现类,会将元素按升序排列;放入treeset中的元素必须实现comparable接口,重写compareTo()方法。
1.3、算法
1.3.1、排序都有哪几种?用JAVA实现一个快速排序
答:排序有冒泡排序、选择排序、快速排序等。
public class QuickSort {
public void quickSort(String[] strDate,int left,int right){
String middle,tempDate;
int i,j;
i=left;
j=right;
middle=strDate[(i+j)/2];
do{
while(strDate[i].compareTo(middle)<0&& i<right)
i++; //找出左边比中间值大的数
while(strDate[j].compareTo(middle)>0&& j>left)
j--; //找出右边比中间值小的数
if(i<=j){ //将左边大的数和右边小的数进行替换
tempDate=strDate[i];
strDate[i]=strDate[j];
strDate[j]=tempDate;
i++;
j--;
}
}while(i<=j); //当两者交错时停止
if(i<right){
quickSort(strDate,i,right);//从
}
if(j>left){
quickSort(strDate,left,j);
}
}
public static void main(String[] args){
String[] strVoid=new String[]{"11","66","22","0","55","22","0","32"};
QuickSort sort=new QuickSort();
sort.quickSort(strVoid,0,strVoid.length-1);
for(int i=0;i<strVoid.length;i++){
System.out.println(strVoid[i]+" ");
}
}
1.3.2、用递归列出目录及其所有子目录下的文件路径---删除目录
public class Test {
public void del(File file){
if(file.isDirectory()){
File[] fs = file.listFiles();
for(File f : fs){
del(f);
}
}
// file.delete();
System.out.println(file.getPath());
}
}
1.4、面向对象
1.4.1、面向对象有哪些特征
答:面向对象的特征主要有以下几个方面:
抽象:抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地
注意与当前目标有关的方面。抽象并不打算了解全部问题,而只是选择其中的一
部分,暂时不用部分细节。抽象包括两个方面,一是过程抽象,二是数据抽象。
继承:继承是一种联结类的层次模型,并且允许和鼓励类的重用,它提供了
一种明确表述共性的方法。对象的一个新类可以从现有的类中派生,这个过程称
为类继承。新类继承了原始类的特性,新类称为原始类的派生类(子类),而原
始类称为新类的基类(父类)。派生类可以从它的基类那里继承方法和实例变量,
并且类可以修改或增加新的方法使之更适合特殊的需要。
封装:封装是把过程和数据包围起来,对数据的访问只能通过已定义的界面。
面向对象计算始于这个基本概念,即现实世界可以被描绘成一系列完全自治、封
装的对象,这些对象通过一个受保护的接口访问其他对象。
多态性:多态性是指允许不同类的对象对同一消息作出响应。多态性包括参
数化多态性和包含多态性。多态性语言具有灵活、抽象、行为共享、代码共享的
优势,很好的解决了应用程序函数同名问题。
1.4.2、静态变量和实例变量的区别?
答:在语法定义上的区别:静态变量前要加static关键字,而实例变量前则不加。
在程序运行时的区别:实例变量属于某个对象的属性,必须创建了实例对象,其中的实例变量才会被分配空间,才能使用这个实例变量。静态变量不属于某个实例对象,而是属于类,所以也称为类变量,只要程序加载了类的字节码,不用创建任何实例对象,静态变量就会被分配空间,静态变量就可以被使用了。总之,实例变量必须创建对象后才可以通过这个对象来使用,静态变量则可以直接使用类名来引用。
1.4.3、final, finally, finalize的区别。
答:final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。
内部类要访问局部变量,局部变量必须定义成final类型。
finally是异常处理语句结构的一部分,表示总是执行。
finalize是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。JVM不保证此方法总被调用
1.4.4、static关键字
答:static 修饰的字段和方法,既可以通过类调用,也可以使用实例调用;
没static 修饰的字段和方法,只能使用实例来调用(建议使用:类名来调用; 其实在底层,对象调用类成员,也会转换类名调用)
static关键字不能与this,super同时连用!
1.4.5、接口和抽象类的比较
答:相同点(都位于继承的顶端,用于被其他实现或继承;都不能实例化;都包含抽象方法,其子类都必须覆写这些抽象方法)
不同点(抽象类为部分方法提供实现,避免子类重复实现这些方法,提供代码重用性;接口只能包含抽象方法;一个类只能继承一个直接父类,却可以实现多个接口)
优先选用接口,尽量少用抽象类;需要定义子类的行为,又要为子类提供共性功能时才选用抽象类

1.4.6、为什么接口中不可以有构造方法,但是抽象类中可以有构造方法
在接口里写入构造方法时,编译器提示:Interfaces cannot have constructors。
A. 构造方法用于初始化成员变量,但是接口没有成员变量。接口是一种规范,被调用时,主要关注的是里边的方法,而方法是不需要初始化的,
B. 类可以实现多个接口,若多个接口都有自己的构造器,则不好决定构造器链的调用次序
C. 在抽象类中可以有构造方法,只是不能直接创建抽象类的实例对象,但实例化子类的时候,就会初始化父类,不管父类是不是抽象类都会调用父类的构造方法,初始化一个类,先初始化父类。
1.5、核心API
1.5.1、 概述String,StringBuffer与StringBuilder的区别
答:String本身是一个代表字符串的类,String是一个常量,定义好之后不可更改;字符串是被共享的。String中提供了一系列操作而不改变原串的方法
StringBuilder是线程不安全的,StringBuffer是线程安全的。---底层实际上是一个字符数组
1.5.2、 String有没有length()这个方法?数组有没有length()这个方法?
答: String有length()这个方法;数组没有length()这个方法,有length的属性。
1.5.3、 两个对象值相同(x.equals(y)==true),但却可有不同的hashcode,这句话对不对?
如果数据是存储在以哈希值作为定位的数据结构,那么当x.equals(y)==true,hashcode必须相等,否则会造成资源的浪费。
1.6、IO操作
1.6.1、流分为哪些类
答:按流动方向的不同可以分为输入流和输出流;按处理数据的单位不同分为字节流和字符流;按功能的不同可分为节点流和处理流。
所有流都继承于以下四种抽象流的某一种

1.6.2、谈谈操作流的步骤
答:首先,用File类找到一个文件对象,得到IO操作的源或目标;其次,通过字节流或字符流的子类创建对象(得到IO操作的通道);之后,进行读或写的操作(IO操作);最后,关闭输入/输出流(打完收工,注意节约资源,关掉)。
由于流的操作属于资源操作,所以在操作的最后一定要关闭以释放资源。
1.7、线程
1.7.1、sleep() 和 wait() 有什么区别
答:sleep就是正在执行的线程主动让出cpu,cpu去执行其他线程,在sleep指定的时间过后,cpu才会回到这个线程上继续往下执行,如果当前线程进入了同步锁,sleep方法并不会释放锁,即使当前线程使用sleep方法让出了cpu,但其他被同步锁挡住了的线程也无法得到执行。wait是指在一个已经进入了同步锁的线程内,让自己暂时让出同步锁,以便其他正在等待此锁的线程可以得到同步锁并运行,只有其他线程调用了notify方法(notify并不释放锁,只是告诉调用过wait方法的线程可以去参与获得锁的竞争了,但不是马上得到锁,因为锁还在别人手里,别人还没释放。如果notify方法后面的代码还有很多,需要这些代码执行完后才会释放锁,可以在notfiy方法后增加一个等待和一些代码,看看效果),调用wait方法的线程就会解除wait状态和程序可以再次得到锁后继续向下运行。
1.7.2、简述synchronized和java.util.concurrent.locks.Lock的异同
答:主要相同点:Lock能完成synchronized所实现的所有功能
主要不同点:Lock有比synchronized更精确的线程语义和更好的性能。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放。Lock还有更强大的功能,例如,它的tryLock方法可以非阻塞方式去拿锁。
1.7.3、线程的生命周期
答:线程的状态有新建、运行、阻塞、就绪、死亡。
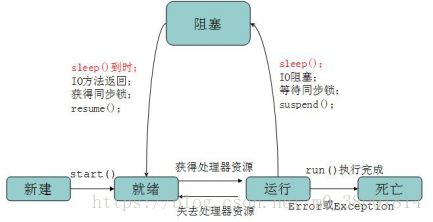
1.7.4、ThreadLocal
ThreadLocal 保证不同线程拥有不同实例,相同线程一定拥有相同的实例,即为每一个使用该变量的线程提供一个该变量值的副本,每一个线程都可以独立改变自己的副本,而不是与其它线程的副本冲突。优势:提供了线程安全的共享对象 与其它同步机制的区别:同步机制是为了同步多个线程对相同资源的并发访问,是为了多个线程之间进行通信;而 ThreadLocal 是隔离多个线程的数据共享,从根本上就不在多个线程之间共享资源,这样当然不需要多个线程进行同步了。
1.8、反射
1.8.1、如何利用反射创建对象
答:使用Class对象的newInstance()方法创建该Class对象的实例,此时该Class对象必须要有无参数的构造方法。
使用Class对象获取指定的Constructor对象,再调用Constructor的newInstance()方法创建对象类的实例,此时可以选择使用某个构造方法。如果这个构造方法被私有化起来,那么必须先申请访问,将可以访问设置为true。
1.8.2、如何使用反射调用方法
答:每个Method的对象对应一个具体的底层方法。获得Method对象后,程序可以使用Method里面的invoke方法来执行该底层方法。
Object invoke(Object obj,Object ... args):obj表示调用底层方法的对象,后面的args表示传递的实际参数。
如果底层方法是静态的,那么可以忽略指定的 obj 参数,该参数可以为 null;如果底层方法所需的形参个数为 0,则所提供的 args 数组长度可以为 0 或 null;如果底层方法返回的是数组类型,invoke方法返回的不是底层方法的值,而是底层方法的返回类型。
素材来源“清茶_”,如侵立删。
标签:惠州北大青鸟惠州JAVA培训惠州IT培训惠州软件培训惠州软件开发

